2. 云计算基础设施¶
这里介绍云计算的基本概念,虚拟存储,弹性计算,容器技术,资源调度等内容,涉及到OpenStack,Docker,Mesos,Hadoop,Ceph等云计算相关的软件,帮助使用者建立一个基于虚拟大数据存储、弹性动态调度的高性能分布式计算平台。
2.1. 云计算概述¶
云计算基础设施提供动态调度的计算资源池可以快速满足用户的计算需要。计算资源池通常包括存储、网络、镜像、实例以及相关的管理、调度、计费和监控、预警等工具。
云计算基础设施的分层
云计算基础设施一般分为IaaS(基础设施作为服务,如虚拟机)、PaaS(平台作为服务,如Web服务器)、SaaS(服务作为服务,如API接口)等几层,也有人提出
DaaS(数据作为服务,如NoSQL服务)和
AaaS(应用作为服务,如Spark)。但在实际部署和应用中,这些层是完全融合在一起的,部分软件往往也可以同时完成多层的功能。
构建自己的IaaS基础设施
构建自己的Iaas云环境并将其提供给用户,需要提供以下几个特性:
- 允许应用用户注册云服务、查看使用情况以及账单。
- 允许开发商和开发人员创建和存储自定义的镜像。
- 允许开发商和开发人员启动、监控、停止虚拟机实例。
- 允许操作人员配置和操作云基础设施,提供API可编程接口。
可以使用在线的云计算服务如Amazon和Aliyun,也可以自己搭建专用的云计算平台。搭建专用云计算平台,可以使用开源的OpenStack或者商用平台。GISpark本着开放、易用的原则,主要选用OpenStack,但其中的各种服务也可以兼容主流的商用平台,或者将其部署到在线的云服务系统之上。
云计算向应用发展的趋势
目前的趋势是,云计算逐步向应用端、为最终用户提供直接服务发展,而不仅仅提供基础设施。这就要求云计算平台不仅提供计算、存贮等资源,还需要提供数据、应用软件、流程与模型等应用层能力,如面向机器学习的应用服务平台。
2.2. OpenStack的安装¶
OpenStack包含块存储系统、对象存储系统、虚拟机镜像管理系统、弹性计算系统以及集成管理控制台等多个子系统(查看 OpenStack软件与体系架构),采用Python编写,使用RabbitMQ作为服务调度总线。OpenStack是一个社区项目,提供开放源码软件,帮助企业运行虚拟计算或者存储云。
OpenStack当前包括三个子项目,三个项目相会独立,可以单独安装(查看OpenStack官方文档,中文安装攻略参考这里,系统架构可以参考这里)。
Swift: 提供对象存储。这是大致类似于Rackspace云文件(从它派生)或亚马逊S3。
Glance: 提供OpenStack Nova虚拟机镜像的发现,存储和检索。
Nova: 根据要求提供虚拟服务。这与Rackspace云服务器或亚马逊EC2类似。
提示:OpenStack在快速演进,一些文档(尤其是中文)可能已经过时,请注意版本差别。
2.2.1. 对象存储服务-Swift¶
OpenStack对象存储是一个在具有内置冗余和容错的大容量系统中按照对象方式存储和检索数据的服务系统,在OpenStack内部用来存储虚拟机镜像。对象存储还有各种应用,如备份或存档数据,存储图形或视频,储存二级或三级静态数据。通过开发与数据存储集成的应用程序,创造弹性和灵活的云存储Web应用程序。
2.2.2. 虚拟机镜像服务-Glance¶
OpenStack镜像服务是一个查找和虚拟机图像检索系统,支持镜像的存储、索引、上传、下载、复制、删除等各种操作。它可以配置三种方式:使用OpenStack对象存储来存储镜像文件,使用亚马逊S3直接存储,或使用S3对象存储作为S3访问中间存储。
2.2.3. 弹性计算服务-Nova¶
OpenStack计算服务是一个云控制器,用来启动一个或一组虚拟实例。Nova从Glance中获取镜像的存储,然后将该镜像投入,然后对该实例的运行状态进行监控、管理。Nova也用于配置每个实例运行期的参数配置,如包含多个实例为某个特定项目的联网(查看OpenStack VLan的部署)。
2.2.4. 管理控制服务-Horizon¶
OpenStack的主要组件如镜像、存储、计算都实现了命令行和API接口(
查看中文解释
命令行参数,API的使用),可以非常容易地通过Shell或者Python脚本进行控制。同时,为了方便系统监控和可视化管理,还提供了基于Web的管理工具-Horizon,可以交互地管理系统中的主要资源(该工具还在发展之中,部分用得较少的功能和参数调节还不能通过Web界面操作),对于网管新手和小型团队还是很方便的,适合快速入门使用(安装参考在Ubuntu16.04上安装Horizon)。
2.2.5. 自动部署和管理OpenStack¶
OpenStack体系非常庞大,涉及到大量的软件,安装过程相对繁琐和复杂,而且容易引起版本的兼容性问题。因此,很多社区都发展出了一些自动化的部署和管理工具,可以提升OpenStack基础设施建立和管理的效率。
OneStack一键自动化部署OpenStack工具。OneStack目前能够完整而正确在Ubuntu12.04(precise)安装部署OpenStack。一键完整部署OpenStack,可以自定义配置,无需交互;安装过程不需要等待提示和输入配置,mysql密码可以自行配置,也可以使用默认的,不需要等待mysql等程序安装的提示;数据库密码可以自行配置,全部完整安装和部署;网络配置可以自行定义;配置文件和依赖关系已经处理;设置变量配置kvm或者虚拟机配置qemu;默认安装一个Ubuntu12.04的操作系统镜像,并启动一个实例,通过运行状态可以查看是否正确部署和运行;通过dashboard进行web管理和查看,或者nova命令管理。
FuelWeb-OpenStack自动化部署工具。FuelWeb中文版是由TryStcack社区联合Mirantis公司开发的OpenStack部署工具。支持Red Hat® 企业版Linux® 和Grizzly版OpenStack®平台。最新特性包括简单快速部署OpenStack云平台(查阅Fuel文档):(1)部署和HA配置支持,支持最新的RedHat企业版本;(2)OpenStack健康检查,部署后会对云平台进行相关测试,并对OpenStack核心组件和Fuel提供的部署配置工具使用的额外的包进行验证;(3)单一的集成包,包括Fuel图形控制界面和命令行脚本,可以通过单独的ISO或IMG获取;(4)提升HA弹性,通过Pacemaker提供的高可靠性服务,以及Clusterlabs开发的可扩展的集群资源管理器提供;
Solum-云服务应用和集成到用户的工具。Solum是专为OpenStack设计的,使OpenStack云服务能更简单的应用和集成到用户的应用开发过程中。Solum利用现有OpenStack服务,比如
Heat, Nova, Glance, Keystone,
Neutron等等,通过一个push按钮就可以转换代码到一个OpenStack云上的管理应用程序中。Solum
是一个社区驱动的项目。这个项目源于各大社区的合作讨论,主要贡献者来自:Rackspace,
eBay, dotCloud, Cumulogic 和 CloudSoft等。
Tempest为云计算平台OpenStack提供集成测试。Tempest为云计算平台OpenStack提供集成测试的开源项目,基于 unittest2 和 nose 建立的灵活且易于扩展及维护的自动化测试框架,使得 OpenStack 相关测试效率得到大幅度提升。
openstack-ops-tools管理Openstack的业务工具和实用程序。openstack-ops-tools用于管理 Openstack 的业务工具和实用程序。是一个Python编写的工具包,用于执行OpenStack管理上的自动化操作。
2.3. 数据虚拟化存储系统¶
虚拟化的存储系统将传统的硬件磁盘集群通过软件来实现,并提供跨多台机器的多个硬盘的统一访问接口,并提供并发访问、冗余存储和多设备容错、分布式内存缓存等分布式存储的高级特性。虚拟存储系统有的提供POSIX文件接口可以像本机文件一样访问,有的提供专用编程接口API和SDK,有的提供REST网络访问接口,有的提供SQL引擎的查询接口。虚拟存储系统从实现的接口层次上可以分为三种:1、块存储,提供类似于“裸盘”磁盘块的访问方式;2、对象存储,提供类似“文件”或者“数据包”的访问接口;3、列存储,提供类似于数据库的“表”和“记录”的访问接口。
2.3.1. 虚拟块存储设备¶
2.3.1.1. iSCSI网络存储设备¶
iSCSI设备通过IP网络连接磁盘,并虚拟为一个统一的物理设备。技术已经相当成熟,并形成了配套的硬件体系。用户可以直接购买硬件化的存储设备,也可以安装相应的软件将一台Linux服务器转化为一个网络存储设备。iSCSI在云计算概念出现之前就已存在,是一个底层的网络磁盘协议实现,旨在构建一个网络无关的“大容量物理磁盘”,磁盘必须使用专用的格式进行管理。
2.3.1.2. Cinder虚拟存储服务¶
Cinder (中文介绍)虚拟存储服务是一个框架,可以将多种存储融合为一个统一的“卷”进行管理和使用,因此可以充分利用各种现有的存储系统资产。当然,强大兼容性的代价是性能会有所影响。Openstack从Folsom开始使用Cinder替换原来的Nova-Volume服务,为OpenStack云平台提供块存储服务。
Cinder服务的组成
- API service:接受和处理Rest请求,将请求放入RabbitMQ队列。提供Volume API V2。
- Scheduler service: 处理任务队列的任务,并根据预定策略选择合适的Volume Service节点来执行任务。目前版本的cinder仅仅提供了一个Simple Scheduler, 该调度器选择卷数量最少的一个活跃节点来创建卷。
- Volume service: 该服务运行在存储节点上,管理存储空间。每个存储节点都有一个Volume Service,若干个这样的存储节点联合起来可以构成一个存储资源池。
Cinder服务的驱动
为了支持不同类型和型号的存储,当前版本的Cinder为Volume Service如下drivers。当然在Cinder的blueprints当中还有一些其它的drivers,以后的版本可能会添加进来。
本地存储:LVM, Sheepdog
网络存储: NFS, RBD (RADOS)
IBM: XIV, Storwize V7000, SVC storage systems
Netapp: NFS存储
ISCSI存储则需要OnCommand 5.0和Data ONTAP 7-mode storage systems with installed iSCSI licenses。
EMC: VNX, VMAX/VMAXe
Solidfire: Solidfire cluster
Cinder服务的部署
上述的Cinder服务都可以独立部署,cinder同时也提供了一些典型的部署命令:
cinder-all: 用于部署all-in-one节点,即API, Scheduler, Volume服务部署在该节点上。
cinder-scheduler: 用于将scheduler服务部署在该节点上。
cinder-api: 用于将api服务部署在该节点上。
cinder-volume: 用于将volume服务部署在该节点上。
2.3.2. 虚拟对象存储系统¶
对象存储提供类似“文件”或者“数据包”的访问接口,一般建立在操作系统的文件系统之上,让访问者可以存取一个“巨大的文件仓库”,而不用关心具体的文件如何组织、存放在何处。对象存储系统一般还提供冗余存储、并行访问、故障转移、动态备份等特性,可以通过专用软件、SDK或者文件系统接口、Web应用等来进行访问。
由于对象存储的多份拷贝需要处理一致性问题,往往写入时较慢,而读取时可以并行访问速度可以很快,适合于写入少、读写多的场合,比如互联网站的日志分析、数据挖掘等场合使用。对于高速写入的实时数据,则需要设计数据分区策略和采用适当的并行写入措施,才能更好地适应流数据的处理模式。
2.3.2.1. HDFS 分布式文件系统¶
HDFS(Hadoop Distributed File System)是Hadoop的基础存储系统,其HBase列存储系统和MapReduce分布式处理系统都建立在HDFS之上。HDFS通过建立Master和Slave节点,将多个节点的磁盘整合为一个统一的资源,并将数据目录(相当于单机的“文件分配表”)保存在Master节点上,从而建立一个跨越多个节点和存储设备的虚拟化的“文件系统”。HDFS将数据划分为“块”,在多个节点保存至少三个拷贝,读取时可以从多个节点同时读取。因此,HDFS分布式文件系统具有较高的“读文件”吞吐率,可以获得较高的读访问带宽。HDFS也支持通过Web接口和文件接口进行访问(效率不算高)。
HDFS已经发展多年,已经在互联网领域大量使用,相对来讲比较稳定可靠。但也存在一些缺点,一直以来未得到有效的改进,包括:由于HDFS保存多个拷贝,导致写入数据时也需要写入多个备份而导致花费较多的时间,因此不适合需要数据大量写入的场合;虽然数据冗余存储,但数据目录保存在Master,如果Master节点失效,将导致整个存储系统失效;如果有大量小文件写入,将导致Master节点的内存占用和查找时CPU占用急剧增长,性能大幅下降。对于快速变动、时效性强而单次数据量小的流式数据处理,不太适合采用HDFS进行存储,而对于存档(不再修改)的图像、视频、打包的日志等大文件较为适合,能提供较大的带宽。
2.3.2.2. Ceph 分布式文件系统¶
Ceph在一个统一的系统中同时提供了对象、块、和文件存储功能。Ceph是加州大学Santa Cruz分校的Sage Weil(DreamHost的联合创始人)博士论文期间设计的分布式文件系统。自2007年毕业之后,Sage开始全职投入到Ceph开发之中,使其能适用于生产环境。Ceph的主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,使数据能容错和无缝的复制。这篇文章探讨了Ceph的架构,它的容错实现和简化海量数据管理的功能。
Ceph在标准POSIX文件接口之上提供大规模分布式文件管理能力,使任何操作系统可以像访问本地文件系统一样访问网络存储。2010年3月,Linus Torvalds将Ceph client合并到内核2.6.34中。2016年,在Ubuntu16.04版本也将Ceph纳入了其发行版中。Ceph的中文文档较为完整,Ceph中文社区也有大量的资源和使用经验分享。
Ceph的相关工程包括(使用OSChina搜索):
- Calamari 是 Ceph 的管理和监控服务,输出REST API。访问Calamari通过客户端代码。
- ceph-dash 是用 Python 开发的一个 Ceph 的监控面板,用来监控Ceph的运行状态,同时提供REST API来访问状态数据。
- Inkscope 是一个 Ceph 的管理和监控系统,依赖于Ceph提供的API,使用MongoDB来存储实时的监控数据和历史信息。
- autobuild-ceph包含一组脚本和一个fabric文件 (fabfile.py) 用来远程部署Ceph以及Ceph的自动构建。
- ceph-deploy 是一个Ceph的简易部署工具,可以非常方便的部署Ceph集群存储系统。
- ceph-zabbix 是一个 Zabbix 插件,用来监控 Ceph 集群文件系统。
2.3.2.3. FastFS 分布式文件系统¶
FastDFS是一个开源的分布式文件系统(中文社区),它对文件进行管理,包括文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
- FastDFS同时对文件的meta data进行管理。
- 文件的meta data就是文件属性,以键值对(key value pair)方式表示: 如:width=1024,其中的key为width,value为1024。
- 文件meta data是文件属性列表,可以包含多个键值对。
FastDFS服务端有两个角色:跟踪器(tracker)和存储节点(storage)。跟踪器主要做调度工作,在访问上起负载均衡的作用;存储节点存储文件,完成文件管理的所有功能,如存储、同步和提供存取接口。跟踪器和存储节点都可以由一台或多台服务器构成。跟踪器和存储节点中的服务器均可以随时增加或下线而不会影响线上服务。其中,跟踪器中的所有服务器都是对等的,可以根据服务器的压力情况随时增加或减少。
FastDFS支持大容量存储,存储节点(服务器)采用了分卷(或分组)的组织方式。FastDFS中的文件标识分为两个部分,卷名和文件名,二者缺一不可。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
2.3.3. NoSQL存储系统¶
广义的NoSQL存储系统包括除了传统的关系数据库和文件系统之外的各种存储系统,包括K-V存储、文档数据库、分布式内存系统以及XML数据库、JSON数据库等。XML数据库、JSON数据库更类似于增强的文件系统,近年来的成熟产品不多,使用范围较小,而且能比较容易被其它类型存储系统取代。这里重点介绍以K-V存储为代表的NewSQL存储系统(虽然体系架构不同于传统数据库,但其支持传统的SQL查询,现在更多地被称为NewSQL而不是NoSQL)。
2.3.3.1. MongoDB¶
MongoDB是典型的NewSQL产品(文档),是非关系数据库当中功能最丰富,最像关系数据库的。MongoDB支持的数据结构非常松散,类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
1.面向集合存储,易存储对象类型的数据。模式自由。
2.支持查询,支持动态查询。支持完全索引,包含内部对象。
3.使用高效的二进制数据存储,包括大型对象(如视频等)。文件存储格式为BSON(一种JSON的扩展)。
4.自动处理碎片,以支持云计算层次的扩展性。
5.支持RUBY,PYTHON,JAVA,C++,PHP等多种语言。
6.可通过网络访问,支持复制和故障恢复。
所谓”面向集合”(Collection-Oriented),意思是数据被分组存储在数据集中,被称为一个集合(Collection)。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定 义任何模式(schema)。模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各中复杂的文件类型。我们称这种存储形式为BSON(Binary Serialized dOcument Format)。
MongoDB服务端可运行在Linux、Windows或OS X平台,支持32位和64位应用,默认端口为27017。MongoDB把数据存储在文件中(默认路径为:/data/db),为提高效率使用内存映射文件进行管理。推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB。
Mongodb Management Studio 功能如下:
1.服务器管理功能,添加服务器,删除服务器 2.服务器,数据库,表,列,索引,树形显示和状态信息查看 3.查询分析器功能,支持select,insert,Delete,update 4.索引管理功能,支持列名的显示,索引的创建,查看,删除. 5.数据库Profile管理,可以设置Profile开关,查看Profile信息.自定义分页大小. 6.master/slave信息显示。
MongoDB的其它工程可以使用OSChina搜索查看。
2.4. Docker计算容器系统¶
Docker提供应用运行的“容器”,能够提供类似于虚拟机的环境隔离的效果,但是通过cGroup技术直接在内核上执行,因此性能上有较好的表现。Docker的运行代码也称为“镜像”,但与虚拟机不同的是,镜像是由多个“层”组合在一起构成的,底层的“层”可以在应用镜像间共享,因此会大大减少需要下载的数据量和启动一个镜像的运行时间。Docker是完全开源的(源代码。目前,类似于Docker的“容器技术”已经有多种实现,包括Ubuntu上面的LXD和CoreOS的Rocket等。
Docker的安全性仍然是一个值得注意的问题。由于部分宿主操作系统不支持资源配额,可能引起部分容器资源占用大量资源而导致其它服务出现问题,可以通过监控以及Mesos之类的进行管理;如果导入镜像时引入了含有木马等不恰当的软件,将很难发现和清除;软件出现Bug时将导致容器内进程从沙箱逃逸出来,从而获得主机权限并可以进而控制整个系统,包括其他容器。因此,使用Docker时应只下载值得信任的镜像,建议尽可能使用软件官方镜像,或者自行制作镜像,尽可能建立私有的镜像存储系统,能提供更好的安全性和更快的下载速度。
Docker的核心组件包括Docker Engine、Machine、Compose、Registry、Swarm等,分别执行运行、环境管理、服务编排、镜像存储和集群部署等功能。Docker.IO提供基于Docker的云平台和镜像管理的Docker Hub,通过Registry和Harbor可以搭建私有的Docker镜像库。通过Rancher搭建自己的基于Docker的PaaS平台,实现资源调度、运维、管理等功能。
2.4.1. Docker Engine¶
Docker Engine是整个Docker生态系统的运行时核心引擎,包括镜像的创建、管理和操作,镜像运行时称为容器,容器可以启动、停止或重新连接。Docker Engine是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化,而且不依赖于任何语言、框架或包装系统。
在Ubuntu上安装Docker Engine:
wget -c https://get.docker.com/ -O docker-setup.sh
sudo chmod +x docker-setup.sh
sudo ./docker-setup.sh
在Aliyun上安装后无法启动,主要因为缺省的网段被阿里云系统预分配占用了,手动分配即可:
docker --bip 192.168.100.1/24 daemon &
Docker Engine提供丰富的命令行操作,参见:Docker简明手册。 Docker Engine常见的操作包括:
docker pull ubuntu,下载ubuntu镜像。
docker run -i -t ubuntu /bin/bash,启动一个控制台。
docker images,列出本机的镜像文件。
docker ps,列出运行的容器。
docker ps -a,列出所有的容器。
docker commit <container> <some_name>,将容器存为一个镜像。
Docker可以通过Dockerfile进行自动构建,类似于Makefile,详细参考这里。以下是一个简单的Dockerfile,可以创建在github.com上,提交到Docker hub时,可以自动构建镜像。
FROM ubuntu:14.04
RUN apt-get update
RUN apt-get install -y curl
2.4.2. Docker Machine¶
Docker Machine在Mac OS X和Windows中创建和维护Docker运行环境(Linux下使用Docker系统服务,不需使用Docker Machine)。
安装参考下面的脚本(Ubuntu系统):
wget https://github.com/docker/machine/releases/download/v0.7.0-rc3/docker-machine-Linux-x86_64
-O docker-machine
sudo cp docker-machine /usr/local/bin/docker-machine
sudo chmod +x /usr/local/bin/docker-machine
这个文件存在Amazon上的,很多时候无法访问,Aliyun上也访问不了,解决办法参见阿里云安装Docker。
2.4.3. Docker Compose¶
Docker Compose组合多个Docker容器为一个服务链,如同时启动MySQL实例和Ngnix提供Web服务。
安装Docker-compose:
wget https://github.com/docker/compose/releases/download/1.7.0-rc2/docker-compose-`uname
-s`-`uname -m` -O docker-compose
cp docker-compose /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
启用一个Compose服务(参见教程),包括:
使用Dockerfile来生成容器的镜像。
在docker-compose.yml文件中定义服务,该服务将运行在隔离的环境。
运行`docker-compose up`自动启动所有关联的容器,提供服务。
docker-compose.yml文件如下所示(文件格式详细参考):
version: '2'
services:
web:
build: .
ports:
- "5000:5000"
volumes:
- .:/code
- logvolume01:/var/log
links:
- redis
redis:
image: redis
volumes:
logvolume01: {}
2.4.4. Docker Registry¶
Docker的公共镜像存储Docker hub具有大量的制作好的镜像,可以下载来直接使用(需要注意适用性和安全性)。也可以安装Registry服务来建立自己的私有镜像存储系统。建立专用镜像服务站可以使用Harbor,这是一个VMWare开源的镜像管理系统,提供WebUI,采用Nginx作为前端Web服务器,后台也是采用Registry进行管理。
2.4.5. Docker Swarm¶
Docker Swarm是Docker开发的集群管理软件,可以通过简单的配置将Docker在一个计算机集群上投入运行。除了Swarm,Docker还支持YARN,Mesos,Kubernetes的集群管理和调度机制。
2.4.6. Rancher 容器PaaS¶
Rancher是一个开源的容器管理平台,帮助构建企业私有容器服务,相当于KVM里的Openstack。Rancher是一个完善的开箱即用的容器管理平台。当企业开始去在生产环境部署 Docker 容器时,面临的首个巨大挑战是如何把一组数量众多的开源技术集成在一起。容器管理涉及到的问题领域包括:存储、网络、监控、编排和调度。Rancher开发、集成和贡献了在生产环境中运行容器所需的所有必要技术。
在Rancher Labs,集成和发布容器编排和调度框架,如:Docker Swarm 和 Kubernetes,同时还开发了常用的应用目录,企业用户管理,访问控制,容器网络和持久存储的技术模块。为开发者和运维者同时提供了完整的功能和优异的用户体验。使用 Rancher,企业不需要再为追赶和集成那些,存在于快速发展的容器生态系统中的无穷无尽技术而忧虑。与之相反,他们可以在一次部署 Rancher 之后就把精力都放到如何快速开发应用,和对业务的提高改善上。
详情参考Rancher的安装与配置。中国的云舒网络提供基于Docker的容器云商业服务和技术支持。
2.5. Mesos与自动化执行¶
2.5.1. Mesos集群资源管理¶
Apache Mesos是一个集群管理器,提供了有效的、跨分布式应用或框架的资源隔离和共享,可以运行Hadoop、MPI、Hypertable、Spark。开源中国组织翻译的Apache Mesos中文文档是非常好的资料。
Mesos的商业版由mesosphere提供,开发了一些生产级应用的工具,并提供了预先配置好的Docker镜像,可以快速投入运行。
自行安装和配置Mesos参考 在生产环境中使用Apache Mesos和Docker,部署架构如下。
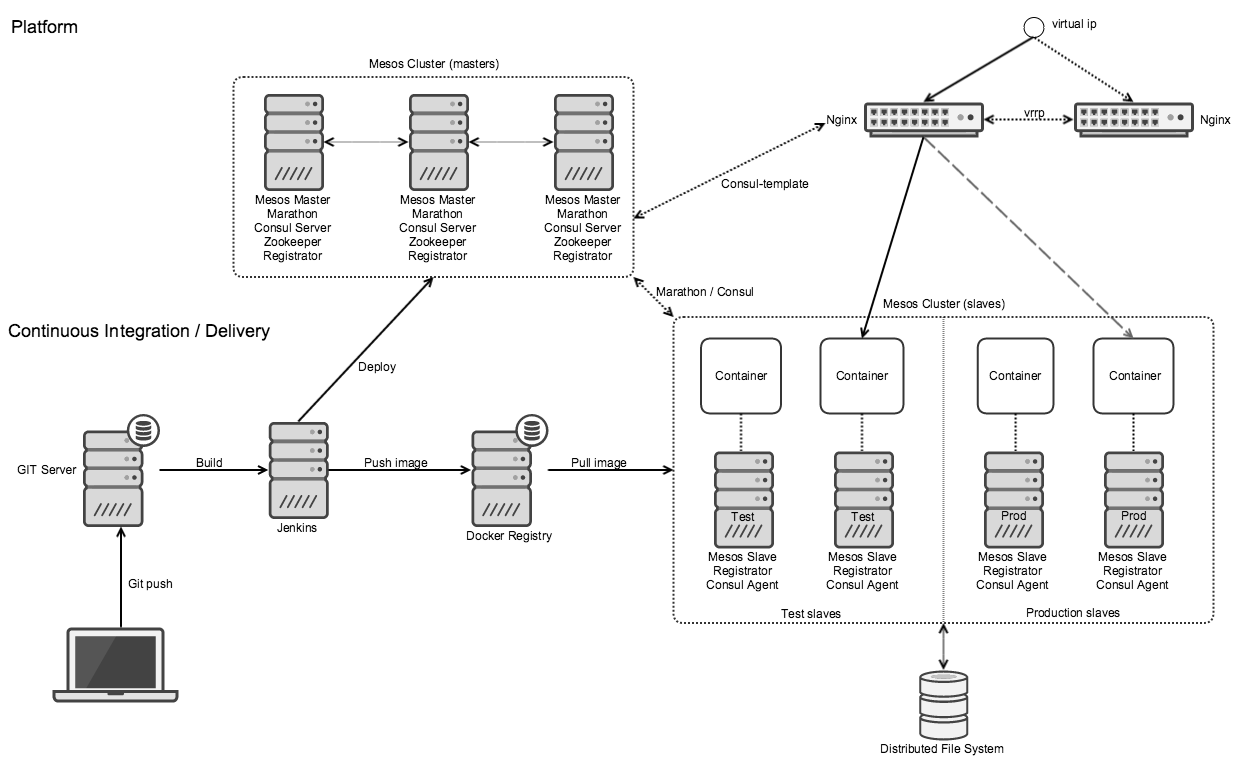
Mesos主要特性:
- Master节点容错,使用ZooKeeper。
- 运行规模支持伸缩到上万个节点。
- 任务之间通过Linux容器技术隔离。
- 基于内存和CPU感知的多资源调度。
- Java, Python 和 C++ APIs。
- Web UI进行整个集群状态的管理。
Mesos可以对节点上的资源统一管理,在不同的应用间进行资源信息收集和多节点任务执行的调度。还可以通过Marathon和Chronos管理调度任务的执行,如日志收集、磁盘清理、数据整理、数据同步、数据挖掘等各种定期工作,并可以通过Docker的容器来执行,还可以调度定期的一个Spark计算任务或者对Spark的计算工作进行排队等等。
2.5.2. Marathon 服务编排¶
Mesos仅仅是适用于集群的管理,这意味着它可以隔离不同的任务负载。但是仍然需要额外的工具来帮助工程师查看不同系统上运行的工作负载。不然的话,如果某些工作负载消耗了所有资源,那么重要的工作负载可能就难以及时地获得资源。
Marathon(马拉松)是一个全新的框架,可以在单一的集群上运行不同的应用程序。它的设计宗旨就是让用户在同一组服务器之上,更智能地运行多种应用程序和服务——Hadoop、Storm,甚至一个标准的Web应用。Marathon出自于一家初创公司Mesosphere之手,这家公司主要就是想构建一个数据中心操作系统,不过这个系统是运行在Apache Mesos集群管理软件之上,这也是Twitter基础设施的重要组成部分。该公司的联合创始人是前Airbnb的工程师Florian Leibert(也曾在Twitter工作过)和Tobias Knaup。
特性:
- HA – 高可用支持。可以运行多个Marathon schedulers,但同一时间只有被选举出来作为主导者调度执行过程。
- Constraints - 约束,每一个机架、节点只运行一个应用实例等等。
- 服务发现和负载均衡,通过HAProxy或events API。
- 健康检查,检查应用运行的健康状况,通过 HTTP 或 TCP 检查。
- 事件订阅,使你通过 HTTP endpoint 接收通知,例如与外部的负载均衡器接入。
- Web UI,基于浏览器的管理界面。
- JSON/REST API,易于整合和编程控制。
- 基本 Auth 认证和 SSL 加密支持。
- 计量,基于JSON格式的计量数据。
Marathon是一个“元架构”,它可以让Mesos和Chronos变得更好用(参考 Mesos+Marathon+Docker部署),随着Mesos一起运行,并且在运行工作负载的同时提供了更高的可用性,让用户可以添加资源以及自动的故障转移。
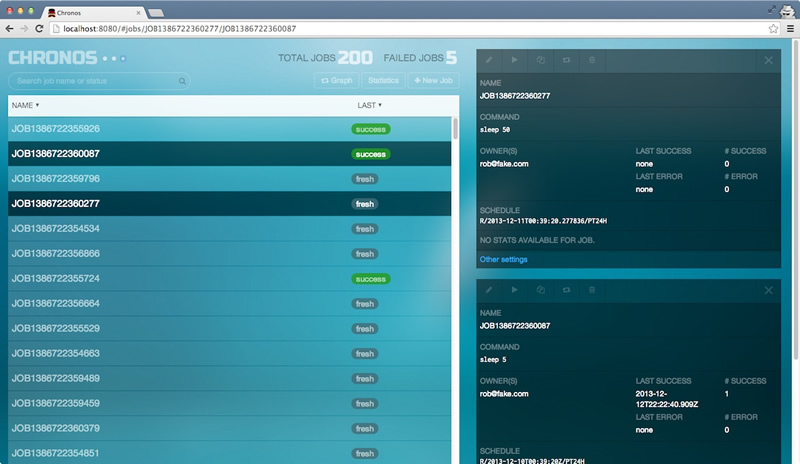
2.5.3. Chronos 任务管理¶
Chronos 是一个具备容错特性的作业调度器,可处理依赖性和基于ISO8601的调度。Chronos是由Airbnb公司推出的用来替代cron的开源产品。你可以用它来对作业进行编排,支持使用Mesos作为作业执行器,支持和Hadoop/Spark进行交互。可定义作业执行完成后的触发器。支持任意长度的依赖链。
特性:
- Web UI 管理器。
- ISO8601 重复任务执行规范。
- 处理依赖性,可以指定任务执行顺序。
- Job执行统计(如:时间占用百分比,成功/失败)。
- 容错(Hot Master)。
- 配置重试-Configurable Retries。
- 多个执行器 (i.e. Mesos Slaves)。